All our products and services are backed by cutting-edge research and the best engineering practices. We have built and delivered state-of-the-art methods for object detection, semantic segmentation as well as efficient unified models. Our expertise lies in both 2D Images and videos as well as 3D Point cloud. For efficiently training our models, we augment our training data with novel generative models.
General Segmenter
Segmentation is a key component of scene understanding. With the aim of bridging the gap between academia and the requirements of industry, we take pride in the research and development of a general segmentation framework to satisfy the real-time computational needs along with high accuracy to help an autonomous system precisely understand the world around it irrespective of ambient weather and lighting conditions. This is currently available on AWS.
General Detector
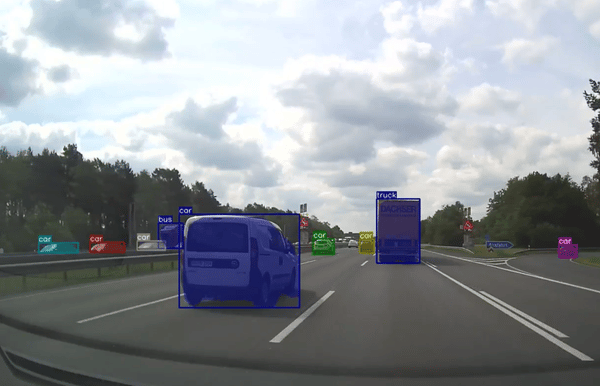
Accurate object detection is one of the most fundamental and challenging tasks for scene understanding. We conduct cutting-edge research to design and develop a general object detection network that not only outperforms the existing state-of-the-art in accuracy and speed, but also detects a wide range of object categories under challenging conditions.
Uninet: Simultaneous Detection and Segmentation
To achieve an optimized real-time scene understanding, in this project, we unify the main components of scene understanding (object detection and semantic segmentation, and depth estimation) using a multi-task learning approach into a single network. The use of a shared feature extraction backbone amongst the task-specific sub-models not only reduces redundancy but also leads to higher accuracy and a significant reduction in resource requirements.
Change Detection
Detection and identification of frequent road infrastructure changes play a critical role in automated mapping and updating. We use state-of-the-art detection, segmentation, and localization techniques to accurately identify changes along a specified route across multiple timelines and incorporate the latest changes to update maps accordingly.
Generative Modeling for Data Generation and Domain Adaptation
One of the major challenges in computer vision is that the model overfits the domain it is trained on and does not generalize well to another domain. It is not possible to capture all the variation in the real world in the training dataset. Therefore, developed novel generative modeling approaches to both generate additional data spanning a variety of ambient lighting and weather conditions and to make our models domain agnostic.
Anonymization of Faces and License Plate
The General Data Protection Regulation (GDPR) is a regulation in EU law on data protection and privacy. The main challenge for video processing is how to process a large amount of data while addressing privacy compliance. To tackle this challenge, our team has created the anonymization tool to anonymize personally identifiable information such as faces and license plates. We trained our model on millions of images, which includes the data captured by our own collection vehicles and edge cases. We emphasize the scalability and automation of the pipeline so that the tool can be efficiently deployed on various cloud platforms and used to guarantee GPDR compliance of visual data. This is currently available on AWS.
Explore our skill sets
Fluid working processes are in our DNA; We welcome any challenge that facilitates growth and collaboration.