In the previous blog, we deep-dived into “Data Challenges in Autonomous Driving and the Need for Drive Data Tags”. In this article, we will look into the challenges involved in building up the driving scene tags.
The amount of information encountered around a vehicle is very complex and extensive. There are two main challenges in creating a catalog of driving scene tags for autonomous vehicles. Firstly, we need to detect, classify, locate, and label various types of information in different driving scenarios, ranging from busy city streets to quiet country roads. There are countless variations in road layouts, traffic patterns, and environmental conditions. Each scenario requires specific tags and annotations for the autonomous vehicle to understand what’s happening. The second challenge is how we organize all the available tags in a standardized way so that we can use the right and relevant data when needed to develop and test specific autonomous driving features.
The Challenges in Identifying and Tagging Diverse Scene Information
Developing an exhaustive taxonomy of data tags for the diverse host of classes is essential in defining a well-established repository of metadata tags insights from the driving scene. Below we list the key different focus areas that help us in the direction of establishing a good taxonomy guide of data tags:
Understand the Operational Design Domain (ODD) in Setting up Data Tag Taxonomy
A critical step in that direction would be in understanding the ODD (Operational Design Domain), which defines the conditions and constraints in which the AD system is expected to operate. That considers factors such as geographical location, weather conditions, road types, and traffic scenarios. Gathering insights from the ODD needs defines the scope of the taxonomy.
To deep dive into how we can categorize the diverse data classes in relationship with the systematic scenario layers, we will take a closer look at each of these types of information with the aid of the PEGASUS method.

- Road geometry information: The AD vehicle needs to understand the layout of the road it’s driving on, including the number of lanes, lane markings, and road signs. This information is crucial for the vehicle to navigate and make decisions about which lane to take and when to turn.
- Traffic infrastructure information: The vehicle must also be aware of the traffic infrastructure, including traffic lights, stop signs, and pedestrian crossings. It needs to be able to detect and recognize these objects accurately to ensure safe and efficient navigation.
- Temporary manipulation information of the road layer and traffic infrastructure layer: Roadworks, accidents, and other temporary obstructions can cause disruptions to the driving scene. The vehicle must be able to detect these changes and adjust its route planning and motion control accordingly.
- Objects on the road: The vehicle needs to be able to detect and identify objects on the road, including static objects that hinder the path of an AD vehicle such as debris on the road, potholes, dead animals, or even a shopping cart left in the parking lot of a supermarket and the dynamic objects such as pedestrians and other vehicles that are in the driving scene of the AD vehicle.
- Environment information: The vehicle needs to be aware of environmental factors that can affect driving conditions, such as weather, road conditions, and lighting. It must be able to adjust its driving behaviour based on these factors to ensure safe and efficient navigation.
The above layers present one way of grouping diverse sets of information into a systematic organization of data tags in relation to the ODD scope of AD functionality.
Analyze Existing Datasets to derive Data tag classes
Analyze the existing datasets collected for AD feature development and validation. These datasets may include sensor data (lidar, radar, camera), GPS information, vehicle dynamics, and more. Examine the data to identify recurring patterns, entities, and events. This analysis helps identify datasets for which specific classes need to be tagged or to be excluded and gain insight into the skewness of data class distribution aiding in setting up a taxonomy list. To gain insights into the data distribution and for domain-specific metrics, Clustering algorithms, such as k-means or hierarchical clustering, can be used to group similar instances based on their features. This can help identify clusters with specific characteristics or identify any potential outliers that may affect the data distribution.


Identify Relevant Classes aiding in the development of AD feature development and failure improvement
Based on the feature development needs for training new functions or improving functions on certain failure cases, identify the relevant classes that need to be included in the taxonomy. These classes can represent objects (e.g., vehicles, pedestrians, cyclists), road elements (e.g., traffic signs, traffic lights, road markings), environmental conditions (e.g., weather, lighting), and other relevant entities. To find specifically those data points where the retraining of the development and validation of the algorithm could be meaningful has to be introduced in the classes of taxonomy.
Iterative Refinement to extend the taxonomy of data tags
The initial taxonomy may not be perfect, and refinement is an ongoing process. Hence analyzing the feedback from data annotation teams and considering their input on potential missing classes, misclassifications, or ambiguities is essential in the upkeep of the data tags taxonomy list. Continuously refine the taxonomy based on the evolving needs of the AD development and validation process.

Challenges in Organizing data tags
Once the data tags are available for a host of diverse classes across vast collected data, it presents a different set of challenges in handling and organizing the available data tags to be made accessible to the user to fetch the relevant data tags source data as per the required feature development and validation. This could be for example user wanting to find video files corresponding to an ODD which have data points in a “vehicle driving in an urban environment on a sunny day driving with pedestrians on the crosswalk in the presence of traffic light“. This example alone requires the queried tags to be searched, filtered, and traced to be inclusive to those source material that needs to be quickly made available to the user. Let us look into some of the strategies which focus on these challenges:
Hierarchical Structuring
The need for organizing the identified classes hierarchically to create a structured taxonomy. Define parent-child relationships and group-related classes together. For example, under the “Vehicle” class, you may have sub-classes like “Car,” “Truck,” and “Motorcycle.” This hierarchical structure provides a logical organization and facilitates efficient tagging and searching. Further granularity can also be achieved by adding insights to specifically fetch a scene of frames where there is a larger density of cars or pedestrians if needed.
Future Scalability
Anticipating the taxonomy’s future scalability requirements is essential; with that flexibility in data organization and usability becomes critical. As AD technology evolves, new classes may emerge, and taxonomy may need to accommodate them. Hence designing the taxonomy of data tags and data organization to be flexible and extensible, allowing for the addition of new classes without disrupting the existing structure. Potential cross-referencing between classes to capture complex relationships and dependencies.
Data Standardization & Harmonization of Data Tags
Datasets collected from different sources like video recordings, and GPS data may have varying data formats, metadata, and tagging conventions, making it difficult to organize and search effectively. Hence establishing a standardized data format, schema, and tagging conventions becomes necessary. To ensure interoperability between different host platforms (FitftyOne, SiaSearch, etc), ASAM is working on the eco-system that incorporates the above-discussed concepts through the OpenLabel, OpenODD standards. This is a good example of where integrating a taxonomy system format with data tags can be efficient and effective for usability and deployment. Standardization on the ODD taxonomy can also be referred to with ISO 34503, BSI PAS 1883. Currently, an industry standard on this scope is yet to be finalized and accepted globally hence it further makes it complex to have a one-approach fits-all customer use cases solution.

Image source: https://www.asam.net/standards/detail/openodd/
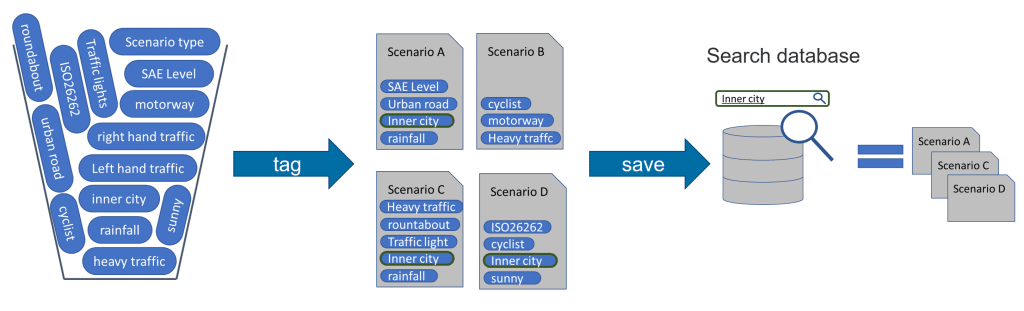
Image source: https://www.asam.net/standards/detail/openodd/
Ease of integration, consumption, and usability of Data Tags as per users’ need
Considering the use cases where one of the users is set out to identify the relevant data sets from criteria of ODD tags and fetch the data sample with a simple query and search functionality and another set of users needs to have an overview of the diverse classes of data points in available datasets to determine the completeness or incompleteness of the overall quality of data that is available to take further actions on downstream activities like curation, data labelling. Presenting different user needs to be factored into from a consumption and usability perspective.
The other critical need emerges with the integration of data tags generated into different DBMS platforms, critically to allow the user to search, query, and filter specific classes or combinations of classes of interest if needed to also trace the source collection and origin of the data and export the data for any downstream activities on data curation for training and validation of algorithms towards AD functionality deployment.
Access levels based on authorization for certain roles also need to be incorporated depending on the user’s role and needs. An AI engineer’s needs for data curation are different from a drive planning coordinator’s need on gathering insights from the current data collection plan progress.

Conclusion
Constructing driving scene tags is a complex task, given the vast amounts of data points generated by various sensors mounted on the AD vehicle. It involves capturing the different classes of information and detecting them to generate the tags on top of the collected data. Tagging various classes of interest and organizing these tags to be consumed for AD functional developers is vital in making the vast collected data useful for downstream work. In this blog, we have tried to break down the challenges and needs in scoping the drive data tags and setting the data tags for being useful for the users as per their needs. In our next blog, we will provide insights into our solution “DriveTag AI” on how we tackle the problems of building up large-scale Drive Scene tags, focusing on providing value addition for the large volume of test vehicle collection data for AD development.